コロナで暇なので書きます。
o-treetree.hatenablog.com
↑の続き。とりあえず根幹の計算部分から。要点、というかコード見てすぐにわかりそうにないところを抜き出して解説、というかメモを加える。
プログラムはgithubにあります。
GitHub - oha-yashi/sudoku: ナンプレ攻略プログラム
calc
ナンプレ盤面のデータの取り扱いをする
calc.h
typedef unsigned short np;
盤面データは前回書いた通り16ビットのビット列で扱うのでunsigned shortをnp型として使う
#define np_reset 0x03fe
#define NUM(d) ((d)>>12)
#define FLAG(d, i) ((d)>>i & 1)
#define set_num(d, i) d = d & 0x0fff | (i<<12)
#define flag_on(d, i) d |= 1<<i
#define flag_off(d, i) d &= ~(1<<i)
#define LINE(n) ((n)/9)
#define ROW(n) ((n)%9)
#define BLOCK(n) (LINE(n)/3*3 + ROW(n)/3)
#define LINE_ST(n) ((n)/9*9)
#define ROW_ST(n) ((n)%9)
#define BLOCK_ST(n) ((n)/27*27 + (n)%9/3*3)
#define BLOCK_N_ST(n) ((n)/3*27 + (n)%3*3)
見たまま。関数にするほどでもないものをマクロで定義している。
#define FLAG(d, i) ((d)>>i & 1)は、条件式に突っ込むだけならd & (1 << i)でも良いんだけど、あとでフラグの数を数えるので1/0で返るようにした。
0b1000 & (1 << 4) --> 0b1000 & 0b1000 --> 0b1000
0b1000 >> 4 & 1 --> 0b0001 & 1 --> 0b0001
#define BLOCK_N_ST(n) ((n)/3*27 + (n)%3*3)は、0~8のブロック番号から、そのブロックの開始マスを得る。
calc.c
int sumKouho(int n){
int sum = 0;
for(int i=1; i<=9; i++){
sum += FLAG(data[n],i);
}
return sum;
}
さっきフラグを数えるといっていたやつ。マス目の候補の数を求める。
void checkNumAll(){for(int n=0;n<81;n++)if(sumKouho(n)==1)for(int j=1;j<=9;j++)if(FLAG(data[n],j))inputNum(n,j);}
ふざけて1行にしただけ。見やすくするとこうなる
void checkNumAll(){
for(int n=0;n<81;n++){
if(sumKouho(n)==1){
for(int j=1;j<=9;j++){
if(FLAG(data[n],j)){
inputNum(n,j);
}
}
}
}
}
全部、直接のネストなので1行にまとめられる
void delete_data(int n){
...
マスnを削除する。単にそのマスを消すだけだと、周辺で消してしまった候補を復活させられないので、一旦全部のマスの数字(空きor確定数字)を保存しておいて、全部リセットして書き直す
void delete_lrb(int n, int byA, int byB, char c){
int i, j, start, roop;
switch(c){
case 'l': start = LINE_ST(n); break;
case 'r': start = ROW_ST(n); break;
case 'b': start = BLOCK_ST(n); break;
}
for(i=0; i<3; i++)for(j=0; j<3; j++){
roop = start + i*byA + j*byB;
if(roop == n){
continue;
}else{
flag_off(data[roop], NUM(data[n]));
}
}
}
走査は前に書いたナンプレの走査法でやる
マスnに対して、そのマスが含まれる行・列・ブロックでNUM(data[n]) = マスnに確定した数字を候補から外す。
関数の名前に_lrbをつけているのは、走査方法を指定して行・列・ブロックに適用できる関数で、変数を変えてそれぞれの方向に走査する。
void delete_check(int n){
delete_lrb(n, 3, 1, 'l');
delete_lrb(n, 27, 9, 'r');
delete_lrb(n, 9, 1, 'b');
}
↑これ。行に対してdelete_lrbをやるのがdelete_lrb(n, 3, 1, 'l');。
以下略。
void inputNum(int n, int input){
if(input != 0){
set_num(data[n], input);
flag_on(data[n], input);
for(int i=1; i<=9; i++){
if(i != input)flag_off(data[n], i);
}
delete_check(n);
}else if(input == 0){
data[n] = np_reset;
}
}
根幹の、数字を確定させる関数。
int isOnlyOneIn_lrb(int start, int find, int byA, int byB){
int sum = 0;
for(int i=0; i<3; i++)for(int j=0; j<3; j++){
if(FLAG(data[start+i*byA+j*byB], find)) sum++;
}
return (sum==1) ? 1 : 0 ;
}
行・列・ブロックの中で、findを候補とするマスが1つしかない時、1を返す。
void findAllOnlyOne(){
...
全マス全候補1~9で全方向に走査して、どれかの方向でOnlyOneと判断したらinputNumする
ここからは、数字を確定させるのではなく、候補を消していくための関数。
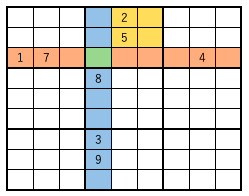
文で説明するとややこしいのでとりあえず図を。

ここでは説明のために、数字3について候補になるところは全部書いている。
さて、この局面では緑マスの候補3は消去できる。左のブロックも、右のブロックも2,3段目に3を入れるしかないので、真ん中のブロックでは2,3段目に3が入ることはできない。
しかし、ここまでの関数では候補を消せず、手動での候補の変更が必要だった。
と言うことでread_delete_lrb関数はこういう局面での候補削減をする。
図の再掲。まず青と黄で塗られた行を見ると、3が候補になるマスは黄色の所のみ。
その行では真ん中のブロックにのみ候補があるので、黄色マスのどこかに3が入るから、真ん中ブロックを見ると緑のマスでは候補3を消せる。
行方向にreadしてブロック方向にdeleteする関数、と言うこと。
void read_delete_lrb(int start, int kouho, int byA, int byB, int byC, char c)
引数について。走査用の変数についてはこちらも参照。「小ブロック」は↓のページで使っている概念。
- start : 走査開始マス。上図では
0
- kouho : 探索する候補。上図では
3
- byA : 走査用の変数。上図の赤矢印。
3
- byB : 同じく。上図の青矢印。
1
- byC : 同じく。上図の緑矢印.
9
- c : 2回目の操作をコントロールするための変数。
上図の局面を解決するためには
read_delete_lrb(0, 3, 3, 1, 9, 'b')
を呼び出す。解説つきで関数の動作を確認。
void read_delete_lrb(int start, int kouho, int byA, int byB, int byC, char c){
int sum[3] = {}; int keep[3] = {};
int i, j, k, roop, sum_all, cont;
sum_all = cont = 0;
for(i=0; i<3; i++){
for(j=0; j<3; j++){
roop = start + i*byA + j*byB;
if(NUM(data[roop]) == kouho) return;
sum[i] += FLAG(data[roop], kouho);
}
sum_all += sum[i];
}
for(i=0; i<3; i++){
if(sum[i] == sum_all){
for(j=0; j<3; j++){
roop = start + i*byA + j*byB;
keep[j] = roop;
}
cont = i+1;
break;
}
}
if(!cont--) return;
switch(c){
case 'l': start = LINE_ST(start + cont*byA); break;
case 'r': start = ROW_ST(start + cont*byA); break;
case 'b': start = BLOCK_ST(start + cont*byA); break;
}
for(i=0; i<3; i++)for(j=0; j<3; j++){
roop = start + i*byB + j*byC;
for(k=0; k<3; k++){
if(roop == keep[k]) goto NEXT;
}
flag_off(data[roop], kouho);
NEXT:;
}
}

このような局面では、まず青マスがあるブロック[0]を走査して、横並びの黄色マスに3が候補として入っているのでその右の緑マスで候補3を消去できる。
これを解決するには
read_delete_lrb(BLOCK_N_ST(0), 3, 9, 1, 3, 'l')
を呼び出す。ブロック[0]の開始マスをstartとして候補3を探索。走査用の変数はブロックを走査するために9, 1、さらに行方向に走査するために3, 'l'を与える。
全部まとめると
void read_and_delete(){
for(int lrb=0; lrb<9; lrb++){
for(int kouho=1; kouho<=9; kouho++){
read_delete_lrb(lrb*9, kouho, 3, 1, 9, 'b');
read_delete_lrb(lrb, kouho, 27, 9, 1, 'b');
read_delete_lrb( BLOCK_N_ST(lrb), kouho, 9, 1, 3, 'l');
read_delete_lrb( BLOCK_N_ST(lrb), kouho, 1, 9, 27, 'r');
}
}
}
こうなる。
void findPair(int start, int byA, int byB){
int i, j, k, l, roop, roop2, cnt;
for(i=0;i<3;i++)for(j=0;j<3;j++){
roop = start + i*byA + j*byB;
cnt = 0;
if(sumKouho(roop)==2){
for(k=0;k<3;k++)for(l=0;l<3;l++){
roop2 = start + k*byA + l*byB;
if(data[roop]==data[roop2])cnt++;
}
if(cnt==2){
for(k=0;k<3;k++)for(l=0;l<3;l++){
roop2 = start + k*byA + l*byB;
if(data[roop2]!=data[roop]){
data[roop2] &= ~(data[roop]);
}
}
}
}
}
}
これは、
の我流解法テクニックBの実装。
data[roop]の候補が2つあって、もう一度走査してdata[roop]と同じdataが2つあったら(data[roop]自体ともう一つ)、再度走査してdata[roop]と中身が同じでないマスで~data[roop]との論理積をとって余計な候補をつぶす。
void only_two_pair_lrb(int start, int byA, int byB){
int i, j, k, l, roop, cnt;
int q_k[10] = {};
for(k=1;k<=9;k++){
for(i=0;i<3;i++)for(j=0;j<3;j++){
roop = start + i*byA + j*byB;
if(FLAG(data[roop], k))q_k[k]++;
}
}
int pair_k_in[10][2] = {};
for(k=1; k<=9; k++){
cnt = 0;
if(q_k[k] == 2){
for(i=0;i<3;i++)for(j=0;j<3;j++){
roop = start + i*byA + j*byB;
if(FLAG(data[roop], k)){
pair_k_in[k][cnt] = roop;
cnt++;
}
}
}
}
for(k=1; k<=9; k++){
if(q_k[k] == 2){
for(l=k+1; l<=9; l++){
if(pair_k_in[k][0] == pair_k_in[l][0]
&& pair_k_in[k][1] == pair_k_in[l][1]){
data[ pair_k_in[k][0] ] = data[ pair_k_in[k][1] ] = 0x0;
data[ pair_k_in[k][0] ] = data[ pair_k_in[k][1] ] |= 1<<k;
data[ pair_k_in[k][0] ] = data[ pair_k_in[k][1] ] |= 1<<l;
}
}
}
}
}
| k-> |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
候補 |
| data[0] |
- |
- |
3 |
- |
- |
- |
- |
- |
9 |
|
3,9 |
| data[1] |
- |
2 |
3 |
- |
- |
- |
- |
- |
9 |
|
2,3,9 |
| data[2] |
1 |
2 |
3 |
- |
- |
- |
- |
- |
9 |
|
1,2,3,9 |
| data[3] |
- |
- |
3 |
4 |
5 |
6 |
- |
- |
- |
|
3,4,5,6 |
| data[4] |
- |
- |
- |
- |
- |
- |
- |
8 |
- |
|
8(確定) |
| data[5] |
1 |
2 |
3 |
- |
- |
6 |
- |
- |
9 |
|
1,2,3,6,9 |
| data[6] |
- |
- |
- |
- |
- |
- |
7 |
- |
- |
|
7(確定) |
| data[7] |
- |
2 |
3 |
4 |
5 |
- |
- |
- |
- |
|
2,3,4,5 |
| data[8] |
1 |
2 |
3 |
- |
- |
6 |
- |
- |
- |
|
1,2,3,6 |
|
|
|
|
|
|
|
|
|
|
|
|
| q_k |
3 |
5 |
7 |
2 |
2 |
3 |
1 |
1 |
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| pair_k_in[k][0] |
- |
- |
- |
3 |
3 |
- |
- |
- |
- |
|
|
| pair_k_in[k][1] |
- |
- |
- |
7 |
7 |
- |
- |
- |
- |
|
|
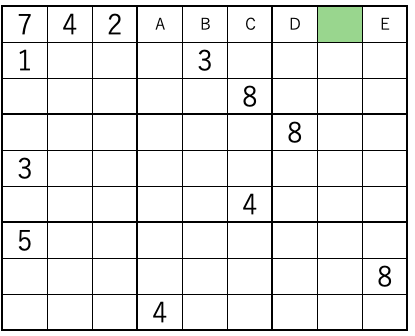
上の表の局面を考える。data[0~8]は走査した9マスを示す。q_kは候補kが走査した中にある数。
- forループその1 --- 走査して候補
kがある数q_kを求める(表を縦に見る)
- forループその2 ---
q_k=2となるkについて、その候補があるマスの場所をpair_k_in[k][2]に格納
- forループその3 ---
q_k=2となるkについて、l = k+1 ~ 9を走査してpair_k_inの組が一致したら、一致したマスで候補をk, lのみにする
以上。これでかなり強力な数独攻略プログラムになった。
「候補を消す関数」ができたので詰むことがなくなって嬉しい。逆に言えば、findPair()やonly_two_pair_lrb()が無いと解けない問題があったことに感謝である。
_lrb式の走査法↓を思いついたのも運がよかった。これがなければコードがクソ長くなってしまっていただろう。
改良版で重要な要素は、あとはファイル入出力くらいかと思うので次はそれについて書こうと思う。
続き↓
o-treetree.hatenablog.com
おしまい。